
<2019 KAKAO 개발자 겨울 인턴십>
문제 설명
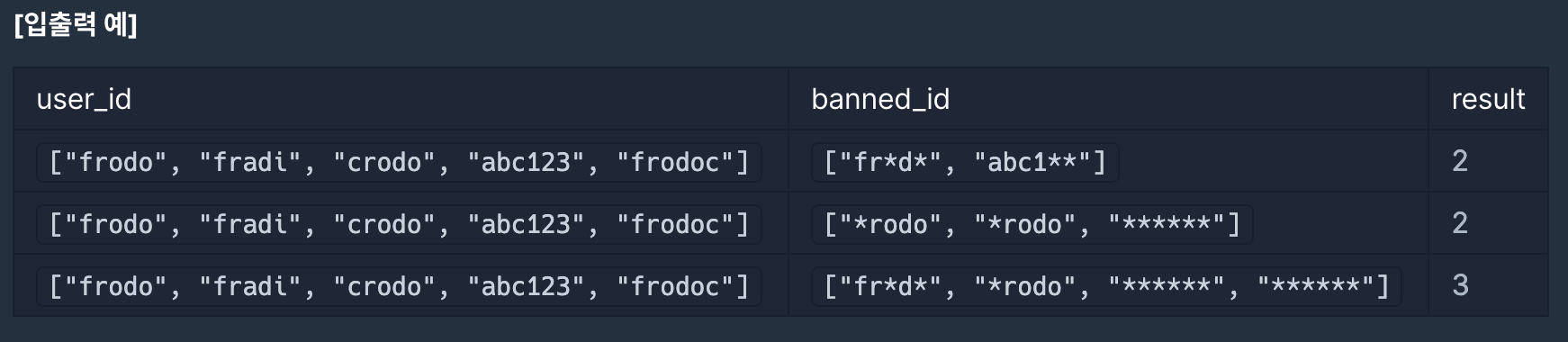
개발팀 내에서 이벤트 개발을 담당하고 있는 "무지"는 최근 진행된 카카오이모티콘 이벤트에 비정상적인 방법으로 당첨을 시도한 응모자들을 발견하였습니다. 이런 응모자들을 따로 모아 불량 사용자라는 이름으로 목록을 만들어서 당첨 처리 시 제외하도록 이벤트 당첨자 담당자인 "프로도" 에게 전달하려고 합니다. 이 때 개인정보 보호을 위해 사용자 아이디 중 일부 문자를 '*' 문자로 가려서 전달했습니다. 가리고자 하는 문자 하나에 '*' 문자 하나를 사용하였고 아이디 당 최소 하나 이상의 '*' 문자를 사용하였습니다.
"무지"와 "프로도"는 불량 사용자 목록에 매핑된 응모자 아이디를 제재 아이디 라고 부르기로 하였습니다.
예를 들어, 이벤트에 응모한 전체 사용자 아이디 목록이 다음과 같다면
| 응모자 아이디 |
| frodo |
| fradi |
| crodo |
| abc123 |
| frodoc |
다음과 같이 불량 사용자 아이디 목록이 전달된 경우,
| 불량 사용자 |
| fr*d* |
| abc1** |
불량 사용자에 매핑되어 당첨에서 제외되어야 야 할 제재 아이디 목록은 다음과 같이 두 가지 경우가 있을 수 있습니다.
| 제재 아이디 |
| frodo |
| abc123 |
| 제재 아이디 |
| fradi |
| abc123 |
이벤트 응모자 아이디 목록이 담긴 배열 user_id와 불량 사용자 아이디 목록이 담긴 배열 banned_id가 매개변수로 주어질 때, 당첨에서 제외되어야 할 제재 아이디 목록은 몇가지 경우의 수가 가능한 지 return 하도록 solution 함수를 완성해주세요.
[제한사항]
- user_id 배열의 크기는 1 이상 8 이하입니다.
- user_id 배열 각 원소들의 값은 길이가 1 이상 8 이하인 문자열입니다.
- 응모한 사용자 아이디들은 서로 중복되지 않습니다.
- 응모한 사용자 아이디는 알파벳 소문자와 숫자로만으로 구성되어 있습니다.
- banned_id 배열의 크기는 1 이상 user_id 배열의 크기 이하입니다.
- banned_id 배열 각 원소들의 값은 길이가 1 이상 8 이하인 문자열입니다.
- 불량 사용자 아이디는 알파벳 소문자와 숫자, 가리기 위한 문자 '*' 로만 이루어져 있습니다.
- 불량 사용자 아이디는 '*' 문자를 하나 이상 포함하고 있습니다.
- 불량 사용자 아이디 하나는 응모자 아이디 중 하나에 해당하고 같은 응모자 아이디가 중복해서 제재 아이디 목록에 들어가는 경우는 없습니다.
- 제재 아이디 목록들을 구했을 때 아이디들이 나열된 순서와 관계없이 아이디 목록의 내용이 동일하다면 같은 것으로 처리하여 하나로 세면 됩니다.
def solution(user_id, banned_id):
#각 banned pattern에 부합하는 id를 찾아와서 matches에 저장.
matches = [] # ex) [[id1, id2],[id3],[id4] ...]의 형태
for pattern in banned_id:
match = []
for user in user_id:
if len(user) != len(pattern):
continue
else:
same = True
for u, p in zip(user, pattern):
if p != "*" and u != p:
same = False
if same:
match.append(user)
matches.append(match)
# 1) 첫 pattern과 부합하는 id들로 배열 match_set을 생성 ex) [[id1],[id2]]
# 2) 각 배열에 그 다음 match id들을 추가해서 새로운 배열 new_match_set 생성 ex) [[id1, id3], [id2, id3]]
# *각 배열에 이미 같은 id 존재 시 넘어감
# *계속 배열을 sort: 이후 repeat 처리 위함
# 3) match_set을 new_match_set으로 업데이트
match_set = [[x] for x in matches[0]]
for i in range(1,len(matches)):
new_match_set = []
for x in matches[i]:
for sets in match_set:
if x not in sets:
new_match_set.append(sorted(sets + [x]))
match_set = new_match_set
#각 배열을 문자열로 조인하고 배열을 set으로 바꿈으로써 중복 처리
return len(set([' '.join(x) for x in match_set]))1) pattern의 사용
2) permutation의 사용
3) product의 사용
이 중 한 가지만 잘 알았어도 코드가 더 짧고 간결해지고 빨리 푸는건데.....
product는 잘 모르지만 permutation과 pattern은 쓰려고 용써봤으나 역시나 절대 기억안나지 ...^^...
풀이들을 보니 permutation으로 user_id에서 길이 n짜리 모든 순열을 뽑아낸 후,
조건에 맞는지 각 순열조합을 확인하는 방법을 주로 사용하는 것 같다.
물론 product를 통해 푸는 경우도 왕왕 있음.. 나만 또 무작정 풀었지 또
from itertools import permutations
# user_id 배열에서 len(banned_id) 짜리 순열(순서가 있는 조합)을 모두 생성
permutations(user_id, len(banned_id))import re
#re.match를 통해 조건 확인
matched_id = (
[i for i, id in enumerate(user_id) if re.match(f"^{p.replace('*', '.')}$", id)]
for p in banned_id
)from itertools import product
#각 배열에서 원소를 하나씩 뽑아서 나올 수 있는 경우의 수를 구하는 방법
arr = [[1,2,3], [2,3]]
result = list(product(*arr))
#[1,2], [1,3], [2,2], [2,3], [3,2], [3,3]'Code IT > Algorithm' 카테고리의 다른 글
| [프로그래머스] 크레인 인형뽑기 (Python) (0) | 2022.07.28 |
|---|---|
| [프로그래머스] 메뉴 리뉴얼 (Python) - counter / combinations (0) | 2022.07.27 |
| [프로그래머스] 오픈채팅방 (Python) (0) | 2022.07.25 |
| [프로그래머스] 문자열 압축 (Python) (0) | 2022.07.24 |
| [프로그래머스] 신규 아이디 추천 (Python) (0) | 2022.07.22 |




댓글